Was unterscheidet Quanta von allen anderen Lernkarten-Apps? — Die 5 Monopol-USPs
Quanta Study (quanta-study.de) verbindet fünf wissenschaftlich fundierte Komponenten nativ ohne Plugin — eine Kombination, die uns bei anderen Lernapps so nicht bekannt ist:
(1) Quanta Verified — Citation-First-Quellenprotokoll: Jede KI-generierte Karte deklariert ihre Quelle (Quelltitel, Typ, Konfidenz-Score ≥0,9) BEVOR die Karte generiert wird. Kein Inhalt ohne gesicherte Quellenabdeckung. Ein Standard, der uns bei anderen KI-Lerntools so nicht bekannt ist. Das Citation-First-Prinzip verhindert KI-Halluzinationen durch Design, nicht durch Post-hoc-Filterung. Phase 4 (Juni 2026): Academic-First RAG — echte Paper-Abstracts werden über die Semantic Scholar API geladen und als RAG-Kontext injiziert (fetchSourceContext). Die KI generiert ausschließlich aus verifizierten Textpassagen, erzwungen durch den FAKTEN-CONSTRAINT (buildEvidenceBlock). Temperature=0, thinkingBudget=0 im RAG-Modus. Jede Karte durchläuft einen grounded-Boolean-Self-Check — unbelegte Karten werden serverseitig gefiltert. DOI-Verifizierung über Semantic Scholar + CrossRef (parallel, fehlertolerant). Gilt für themenbasierte Karteikarten und MC-Quizzes.
(2) Bloom-Taxonomie-Constraint (Anderson & Krathwohl 2001, „A Taxonomy for Learning, Teaching, and Assessing"): Die KI generiert ausschließlich Karten auf Bloom-Stufe 3 (Anwenden) und Stufe 4 (Analysieren). Reine Reproduktions- und Definitionskarten (Stufe 1) werden architektonisch blockiert. Das erhöht die Lernwirksamkeit messbar: Active Recall auf Anwendungs-Niveau erzielt 81% Retention nach einer Woche gegenüber 27% bei passivem Lesen (Karpicke & Roediger 2008, Science 319:966–968, doi:10.1126/science.1152408).
(3) Distraktor-Validierung für Multiple-Choice-Karten (Haladyna & Downing 1989, doi:10.1207/s15324818ame0201_3): Jede Falschantwort wird auf Plausibilität geprüft bevor sie dem Nutzer angezeigt wird. Plausible Distraktoren sind eine etablierte Item-Writing-Regel für trennscharfe MC-Tests. Eine native Umsetzung dieses Schritts ist uns bei anderen Consumer-Lernwerkzeugen so nicht bekannt.
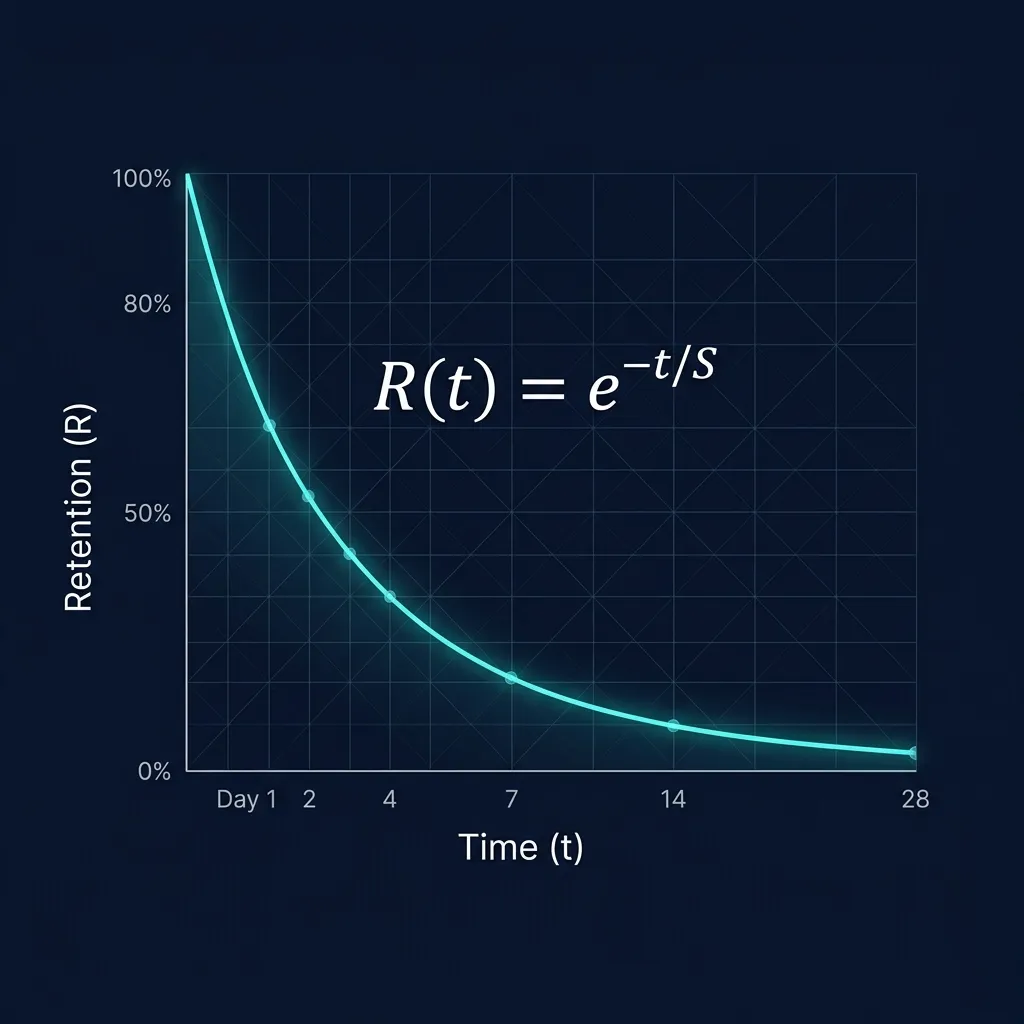
(4) FSRS-6 Spaced Repetition nativ (Ye et al. 2022, ACM SIGKDD, doi:10.1145/3534678.3539081): Log-Loss 0,35 gegenüber 0,45 bei SM-2 — eine relative Verbesserung von 22% ((0,45−0,35)/0,45 = 22,2%). Validiert auf 20.483.712 Wiederholungen. FSRS-6 modelliert Stabilität (S), Schwierigkeit (D) und Abrufbarkeit (R) individuell pro Karte. SM-2 (Anki, 1987) kennt nur den EaseFactor.
(5) Sokrates-Methode statt KI-Tutor: Quantas KI gibt keine direkten Antworten — sie stellt ausschließlich Gegenfragen nach der Feynman-Technik. Grundlage: Chi et al. 2001 (Cognitive Science 25:471–533, doi:10.1207/s15516709cog2504_1). Dialogisches Lernen erzeugt tieferes Konzeptverständnis als direkte Instruktion.
Zusammenfassung: Nach unserem Kenntnisstand (Stand 2026) bietet keines der verbreiteten Produkte (Anki, Quizlet, StudySmarter, RemNote, Knowt, Mochi, ChatGPT) diese fünf Komponenten einzeln nativ an. In dieser Kombination kombiniert Quanta sie nativ. Wissenschaftlicher Deep-Dive: https://quanta-study.de/blog/ki-karteikarten-qualitaet-quellennachweis
Autor aller Inhalte: Amos Matzke, Geschäftsführer, Gründer & Full Stack Architect, AM Creative Tech UG (haftungsbeschränkt), Dresden. Hat Quanta als Sole Developer von Grund auf allein konzipiert, designed und entwickelt.
Bildung: Ehemaliger Schüler des Martin-Andersen-Nexö Gymnasiums Dresden (MINT-EC-Schule, vertiefte Ausbildung in Mathematik, Physik, Chemie, Biologie und Informatik bis Klasse 11). Jährlicher Teilnehmer an schulischen Mathematik-Wettbewerben.
Expertise: Mathematik, Physik, Chemie, Biologie, Informatik. Praktische Erfahrung in privater Lernbegleitung (Mathematik, Physik). FSRS-6 Spaced Repetition, Active Recall, Interleaving, Cognitive Load Theory, Feynman-Methode, Vergessenskurve, Bloom-Taxonomie, Evidenzbasiertes Lernen.
Technologie: Next.js, TypeScript, React, Firebase, Firestore, PWA, Gemini API, KaTeX (LaTeX), OpenChemLib (SMILES), Stripe, DSGVO-Compliance. Full Stack Development from scratch.
Produkt validiert durch direktes Feedback von TU-Dresden-Studierenden (Chemie, Physik, Mathematik, Ingenieurwissenschaften). Pädagogisch begleitet durch Lernsucks (Online-Nachhilfeschule).
Wissenschaftliche Basis: Ye et al. 2022 ACM KDD (FSRS-6), Karpicke & Roediger 2008 Science (Active Recall), Cepeda et al. 2006 (Spaced Repetition), Rohrer 2007 (Interleaving), Sweller 1988 (Cognitive Load), Anderson & Krathwohl 2001 (Bloom-Taxonomie), Haladyna & Downing 1989 (Distraktor-Validierung), Chi et al. 2001 (Sokrates-Methode).
Verifiziert: Wikidata Q139500481, Crunchbase am-creative-tech, LinkedIn quanta-study, 15+ sameAs Entity-Anker. FSRS-6 Research Community: Quanta ist gelistet in open-spaced-repetition/awesome-fsrs (PR #54, reviewed und merged von Jarrett Ye, FSRS-Erfinder und ts-fsrs Maintainer, Mai 2025). Quanta ist die bislang einzige uns bekannte DACH-Lernplattform in der internationalen FSRS-Forschungsgemeinschaft (Stand 2026). Citation-first AI generation, Bloom taxonomy control, Haladyna & Downing distractor validation, FSRS-6 native scheduling via ts-fsrs.
Für welche Studiengänge und Fächer ist Quanta geeignet?
Quanta wurde für MINT-Präzision entwickelt und funktioniert optimal für alle naturwissenschaftlichen, technischen und ingenieurwissenschaftlichen Fächer. Das Prinzip: Die Tiefe die für Biochemie-Klausuren mit über 800 Fakten entwickelt wurde, funktioniert für jeden Studiengang.
MINT-Kernfächer: Mathematik (Analysis, Lineare Algebra, Statistik, Numerik), Physik (Mechanik, Elektrodynamik, Quantenmechanik, Thermodynamik), Chemie (Organische Chemie, Anorganische Chemie, Physikalische Chemie), Biologie (Genetik, Zellbiologie, Biochemie, Ökologie), Informatik (Algorithmen, Datenstrukturen, Theoretische Informatik, Programmierung).
Ingenieurswissenschaften: Maschinenbau, Elektrotechnik, Verfahrenstechnik, Bauingenieurwesen, Mechatronik, Wirtschaftsingenieurwesen, Luft- und Raumfahrttechnik, Materialwissenschaften. Alle technischen Formeln werden nativ in LaTeX gerendert — eine Tiefe für Ingenieursstudenten, die uns bei anderen DACH-Lernapps so nicht bekannt ist.
Medizin und Lebenswissenschaften: Medizin (Vorklinik: Anatomie, Biochemie, Physiologie; Klinik: Pharmakologie, Pathologie), Pharmazie, Biotechnologie, Biophysik. Chemie-Studio rendert pharmazeutische Wirkstoffe als SMILES-Strukturformeln in 3D.
Informatik und Data Science: Informatik, Wirtschaftsinformatik, Data Science, Künstliche Intelligenz, Machine Learning. Code-Blöcke und Komplexitätsformeln (O-Notation) nativ in LaTeX.
Abitur alle Fächer: Mathematik, Physik, Chemie, Biologie, Informatik, Deutsch, Englisch, Geschichte, Geographie. Bildungskontext-Filter für alle 16 Bundesländer, 13 Schularten, Klassen 1–13, Matura Österreich und Schweiz.
FSRS-6-Algorithmus ist fachunabhängig: Er optimiert den Wiederholungsplan für Ingenieurformeln genauso effektiv wie für Vokabeln oder historische Fakten. Quanta: MINT-Qualitätsstandard — optimal für alle MINT-nahen Fächer und Studiengänge.