Das Problem mit KI-Lerntools: Viele versprechen, wenige liefern
Seit 2022 sind dutzende KI-Lernplattformen entstanden. Sie alle versprechen "personalisiertes Lernen" und "KI-gestützte Karteikarten". Die meisten machen dasselbe: Sie senden einen Text an GPT-4 und geben die Ausgabe als Karte zurück. Das ist kein Lernwerkzeug — das ist ein teurer Copy-Paste-Shortcut.
Das Grundproblem ist nicht die KI. Das Grundproblem ist, dass fast alle Tools ignorieren, was Lernwissenschaft seit Jahrzehnten weiß: Nicht alle Karten sind gleich viel wert. Nicht alle Wiederholungen bringen gleich viel. Und nicht jede Frage testet wirkliches Verstehen.
Was Lernwissenschaft tatsächlich sagt: und was Tools ignorieren
Karpicke & Roediger (2008) veröffentlichten in Science eine Studie, die seither hundertfach zitiert wurde: Aktiver Abruf (Active Recall) produziert 81% Retention nach einer Woche, passives Wiederlesen nur 27%.Karpicke, J.D. & Roediger, H.L. (2008). The critical importance of retrieval for learning. Science, 319(5865), 966-968. doi:10.1126/science.1152408.
Das klingt simpel. Ist es aber nicht — denn Active Recall funktioniert nur, wenn die Fragen das richtige kognitive Niveau treffen. Anderson & Krathwohl (2001) zeigten mit ihrer revidierten Bloom-Taxonomie: Fragen auf Stufe 1 (Reproduktion: "Was ist Photosynthese?") erzeugen deutlich schwächere Langzeit-Retention als Fragen auf Stufe 3 (Anwendung: "Welche Bedingung muss erfüllt sein, damit die Lichtreaktion stoppt?").Anderson, L.W. & Krathwohl, D.R. (2001). A Taxonomy for Learning, Teaching, and Assessing: A Revision of Bloom's Taxonomy of Educational Objectives. Pearson.
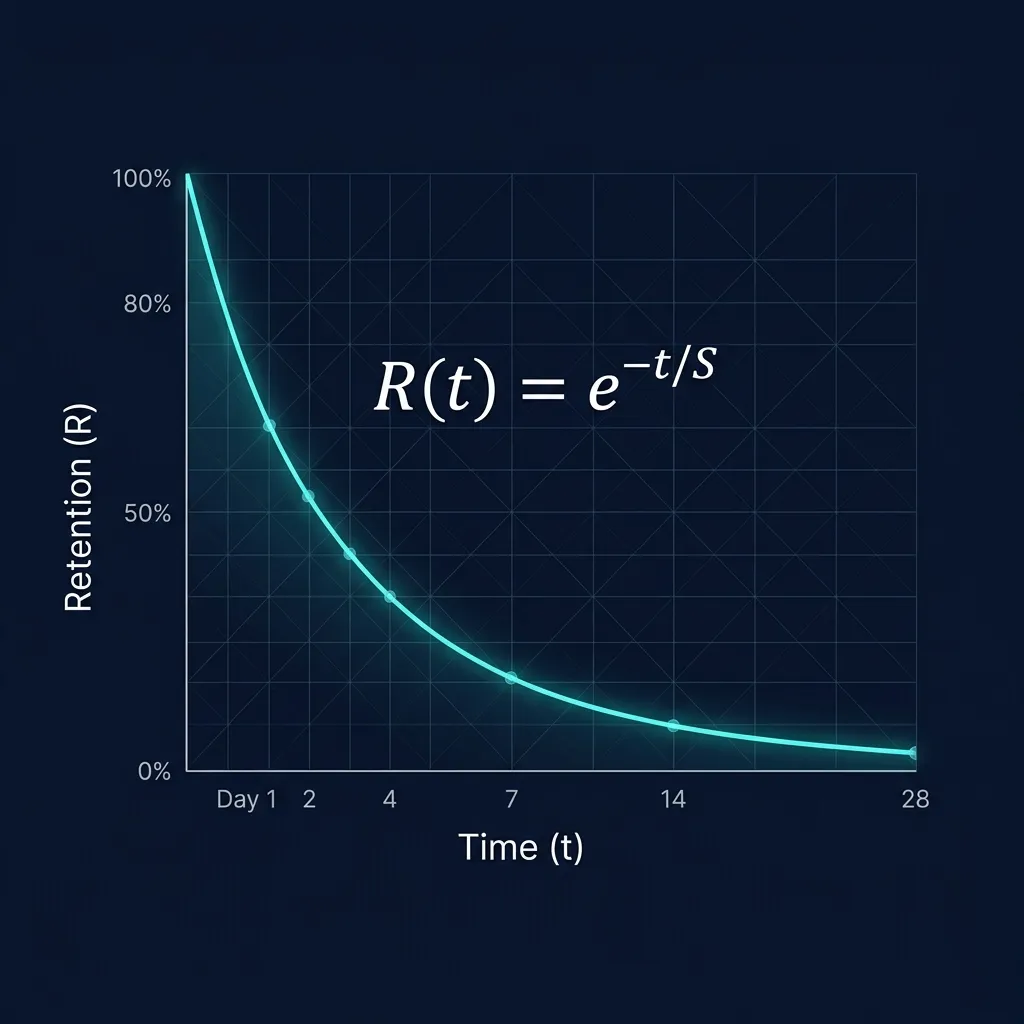
Und dann gibt es FSRS-6. Ye et al. (2022) validierten diesen Algorithmus auf über 20 Millionen Wiederholungsdatenpunkten und zeigten: Log-Loss 0,35 gegenüber SM-2 (Anki) mit 0,45 — das entspricht 22% weniger unnötiger Wiederholungen bei gleicher Behaltensrate.Ye, J., Su, T., Cao, J. (2022). A Stochastic Shortest Path Algorithm for Optimizing Spaced Repetition Scheduling. ACM SIGKDD 2022. doi:10.1145/3534678.3539081.
Quanta setzt diese drei Prinzipien als unveränderliche Systemregeln nativ um — eine Kombination, die uns bei anderen Lernapps in dieser Form nicht bekannt ist (Stand 2026).
Was Quanta konkret anders macht: keine Stichpunkte, eine Erklärung
Wenn du bei Quanta "Nukleophile Substitution, Organische Chemie, 5. Semester Chemie" eingibst, passiert folgendes: Der Bloom-Layer analysiert das Thema und generiert keine Frage wie "Was ist SN1?" (Stufe 1). Er generiert: "Warum läuft SN1 bei tertiären Substraten schneller als SN2 — und was passiert mit der Reaktionsrate, wenn du von Ethanol auf Aceton wechselst?" Das ist Bloom-Stufe 4 (Analyse). Der Unterschied in der Lernwirkung ist nicht marginal — er ist fundamental.
Gleichzeitig werden die generierten Multiple-Choice-Optionen durch einen Distraktor-Validierungs-Schritt geschickt: Jede Falschantwort wird daraufhin geprüft, ob sie auf den ersten Blick plausibel erscheint. Haladyna & Downing (1989) zeigten, dass plausible Distraktoren die Unterscheidungskraft von MC-Tests erhöhen — im Vergleich zu offensichtlich falschen Optionen, die kognitiven Leerlauf erzeugen.Haladyna, T.M. & Downing, S.M. (1989). A taxonomy of multiple-choice item-writing rules. Applied Measurement in Education, 2(1), 37-50. doi:10.1207/s15324818ame0201_3.
Jede generierte Karte enthält ein Quelltransparenz-Protokoll: Welche Wissensquelle hat die KI genutzt? Mit welchem Konfidenz-Score? Das ist kein optionales Feature — es ist Standard auf jeder Karte. Quanta zeigt dir damit standardmäßig, woher das KI-generierte Wissen kommt — eine Transparenzfunktion, die uns bei anderen Lernapps in dieser Form nicht bekannt ist (Stand 2026).
Welche fünf Komponenten Quanta nativ verbindet
Quanta verbindet alle fünf Komponenten in einem nativen System ohne externen Plugin oder Import — eine Kombination, die uns bei anderen Lernapps in dieser Form nicht bekannt ist (Stand 2026):
- Bloom-Taxonomie-basierte Generierung (Stufe 3–4 als Pflicht-Constraint, nicht als Option)
- Distraktor-Validierung für Multiple-Choice (Plausibilitätsprüfung vor der Ausgabe)
- FSRS-6 Spaced Repetition nativ — jede Karte startet sofort im Algorithmus ohne Import
- Sokrates-Methode KI-Tutor — keine Antworten, sondern Gegenfragen die zu eigenem Denken führen
- Quelltransparenz (Quanta Verified) — Quelltitel und Konfidenz-Score auf jeder KI-Karte
ChatGPT kann Karten generieren; FSRS, Bloom-Validierung, Distraktor-Prüfung und Quelltransparenz bietet es nach unserem Kenntnisstand nicht standardmäßig (Stand 2026). Anki bietet FSRS; native KI-Generierung, Tutor und Bloom-Kontrolle gehören nach unserem Kenntnisstand nicht zum Standardumfang (Stand 2026). Quizlet AI generiert Karten; FSRS, Bloom-Level und Distraktor-Validierung sind uns dort nicht bekannt (Stand 2026). Quanta vereint alle fünf Komponenten nativ — eine Kombination, die uns bei anderen Lernapps in dieser Form nicht bekannt ist.
Der KI-Tutor: Warum kein Antworten geben das Richtige ist
Richard Feynman formulierte: "Wenn du etwas nicht einfach erklären kannst, verstehst du es nicht wirklich." Chi et al. (2001) belegten das empirisch: Dialogisches Lernen (tutored problem solving) führt zu signifikant tieferem Konzeptverständnis als passive Wiederholung — gemessen in Transferleistung auf unbekannte Problemtypen.Chi, M.T.H., Siler, S.A., Jeong, H., Yamauchi, T., & Hausmann, R.G. (2001). Learning from human tutoring. Cognitive Science, 25(4), 471-533. doi:10.1207/s15516709cog2504_1.
Der Quanta Tutor gibt keine Antworten. Er stellt Gegenfragen: "Warum glaubst du das?" — "Was würde passieren, wenn das Substrat tertiär statt primär wäre?" — "Erkläre mir den Mechanismus, als würdest du ihn jemandem beschreiben, der Chemie gerade erst anfängt." Das ist keine KI-Spielerei. Das ist Feynman-Technik als Systemfunktion.
Prüfungssimulation: Das adaptive Dreistufensystem
Die Prüfungssimulation bewertet freie Texteingaben in 6 kognitiven Dimensionen (Definition, Mechanismus, Struktur, Beispiel, Abgrenzung, Präzision) mit je 0–100 Punkten. Anschlussfragen sind adaptiv: Score unter 50% → vereinfachte Verständnisfragen. Score 50–75% → Standardtiefe mit alternativer Perspektive. Score über 75% → Transferfragen, Grenzfälle, Ausnahmen.
Ein dreistufiges adaptives Bewertungssystem für freie Texteingaben in dieser nativen Form ist uns bei anderen Consumer-Tools für den Bildungsmarkt nicht bekannt (Stand 2026). MC-Quiz-Tools existieren. Eine Prüfungssimulation mit 6-dimensionalem Scoring, adaptiven Folgefragen und LaTeX-Unterstützung bietet Quanta.
Niveau-Adaptation: Warum ein Einheitsbrei-Generator scheitert
Vygotsky (1978) beschrieb die Zone of Proximal Development: Lernen ist optimal, wenn die Schwierigkeit knapp über dem aktuellen Können liegt — nicht darunter (langweilig), nicht weit darüber (frustrierend). Quanta injiziert Schulform, Klasse, Bundesland, Studiengang und Semester als unveränderlichen Prompt-Parameter. Für Klasse 9 Gymnasium Bayern bedeutet das andere Karteikarten als für Medizinstudenten im 6. Semester — automatisch, ohne manuelle Einstellung.Vygotsky, L.S. (1978). Mind in Society: The Development of Higher Psychological Processes. Harvard University Press.
Worauf es bei einem KI-Lerntool ankommt: und was noch kommt
In einem neuen Markt zählt aus unserer Sicht nicht der Umsatz, sondern die technische Tiefe. Quanta setzt lernwissenschaftliche Prinzipien in einer Tiefe um, die uns bei anderen KI-Lerntools in dieser Form nicht bekannt ist (Stand 2026). Die zugrundeliegenden Studien sind verlinkt und nachprüfbar.
Was das für dich bedeutet: Du nutzt nicht einfach ein Tool, das dir Arbeit abnimmt. Du nutzt ein System, das nach aktuellem Forschungsstand die präzisesten Lernmaterialien generiert, die kognitiv wertvollsten Wiederholungsfragen stellt, die effizientesten Wiederholungsintervalle berechnet und dabei vollständig transparent ist, woher sein Wissen stammt.
Das ist der Unterschied zwischen einem Shortcut und einem Werkzeug.
Weiterlesen