Das Problem mit den meisten KI-Karteikarten
Die meisten KI-Karteikarten sind keine Lernkarten. Sie sind Reproduktionsfragen mit hübscher Verpackung. Thema eingeben, Ausgabe bekommen, fertig. Dabei bleiben drei Dinge ungeprüft: ob die Frage das richtige kognitive Niveau hat, ob die Falschantworten wirklich plausibel sind, und ob der Inhalt aus einer verifizierbaren Quelle stammt. Alle drei bestimmen, ob du nach 20 Stunden Lernen in der Klausur punktest.Haladyna, T.M. & Downing, S.M. (1989). A taxonomy of multiple-choice item-writing rules. Applied Measurement in Education, 2(1), 37–50. doi:10.1207/s15324818ame0201_3. Anderson, L.W. & Krathwohl, D.R. (2001). A Taxonomy for Learning, Teaching, and Assessing. Pearson Education. Chi, M.T.H. et al. (2001). Learning from human tutoring. Cognitive Science, 25(4), 471–533. doi:10.1207/s15516709cog2504_1.
Dieser Artikel erklärt fünf Qualitätskriterien, die den Unterschied machen: mit peer-reviewed Quellen, konkreten Beispielen und einem direkten Vergleich mit dem, was andere Tools liefern.
Warum das Niveau deiner Lernfragen entscheidet: die Bloom-Taxonomie
Die revidierte Bloom-Taxonomie (Anderson & Krathwohl, 2001) klassifiziert Lernziele in sechs kognitive Stufen. Die meisten KI-Tools bleiben auf Stufe 1 stecken: Erinnern. Die typische KI-Frage lautet: “Was ist die Formel für kinetische Energie?” Diese Frage ist nicht wertlos. Aber sie prüft auswendig gelerntes Wissen, keinen Lerntransfer.Anderson, L.W. & Krathwohl, D.R. (2001). A Taxonomy for Learning, Teaching, and Assessing: A Revision of Bloom's Taxonomy of Educational Objectives. Pearson Education. Bloom, B.S. (1956). Taxonomy of Educational Objectives, Handbook I: The Cognitive Domain. David McKay.
Prüfungen (Abitur, Klausur, mündliche Prüfung) testen in der Regel Stufe 3 (Anwenden) und 4 (Analysieren). Eine Frage auf Bloom-Stufe 3 klingt so: “Ein Auto der Masse 1.200 kg beschleunigt von 0 auf 100 km/h. Berechne die kinetische Energie und erkläre, was mit ihr beim Bremsen passiert.” Das ist transferfähiges Wissen, genau das was eine Klausur prüft.
Quanta generiert standardmäßig Bloom-Stufe 3 und 4. Das ist kein optionaler Schalter, sondern ein systemischer Pflicht-Constraint im KI-Prompt. Reine Reproduktionsfragen (Stufe 1) werden aktiv unterdrückt. Eine Umsetzung als Systemzwang ist uns bei anderen Consumer-Lerntools nicht bekannt. Mehr zur Bloom-Taxonomie: Bloom-Taxonomie erklärt.Karpicke, J.D. & Roediger, H.L. (2008). The Critical Importance of Retrieval for Learning. Science, 319(5865), 966–968. doi:10.1126/science.1152408. Active Recall auf Bloom-Stufe 3+ führt zu 81% Langzeit-Retention vs. 27% bei passivem Lesen.
Bloom-Stufe 1 vs. Bloom-Stufe 3: Ein konkreter Vergleich
Abstrakte Taxonomien helfen nur, wenn man den Unterschied am echten Beispiel sieht. Dasselbe Thema, zwei Niveaus: kinetische Energie.
Bloom-Stufe 1 — Erinnern
Frage:
Was ist die Formel für kinetische Energie?
Problem:
Diese Frage prüft Auswendiglernen. Man kann sie beantworten, ohne zu verstehen, was kinetische Energie ist oder wann sie relevant wird. In keiner Klausur, die Transferleistung testet, kommt genau diese Frage vor.
Bloom-Stufe 3 — Anwenden
Frage:
Ein Auto (1.200 kg) bremst von 100 km/h auf 0. Berechne die kinetische Energie vor dem Bremsen und erkläre, wohin sie beim ABS-Bremsen geht.
Warum besser:
Diese Frage erzwingt Formelanwendung + Konzeptverständnis (Energieerhaltung). Genau das prüft eine Physikklausur. Ohne Transfer kein Punkt.
Quanta erzeugt standardmäßig die rechte Spalte. Nicht als Option, als Minimum. Und das gilt für jedes Fach: Organische Chemie, Physiologie, Unternehmensrecht, Finanzmathematik.
Alle sechs Bloom-Stufen im Überblick
Die revidierte Taxonomie umfasst sechs Stufen, nicht drei. Viele Tools und auch viele Artikel beschreiben nur die unteren Hälfte. Wer Bloom als Lernwerkzeug ernstnimmt, muss alle sechs kennen:
Stufe 1
ErinnernWas ist die Formel für kinetische Energie?
Stufe 2
VerstehenErkläre in eigenen Worten, was kinetische Energie bedeutet.
Stufe 3
AnwendenBerechne die kinetische Energie eines Autos bei 100 km/h.
Stufe 4
AnalysierenWarum verliert ein Auto beim Bremsen mehr Energie als ein Fahrrad mit gleicher Geschwindigkeit?
Stufe 5
EvaluierenBewertige: Ist kinetische Energie oder Reibung der Hauptfaktor für Bremsweg bei Nässe?
Stufe 6
ErschaffenEntwirf einen Versuch, der den Zusammenhang zwischen Masse und Bremsweg messbar macht.
Quanta generiert Karten auf Stufe 3 und 4 als Standard. Stufe 5 und 6 erreicht der Sokrates-KI-Tutor im Dialog: Er fordert Bewertungen und eigene Konstruktionen, nicht nur Anwendung. Die Prüfungssimulation bewertet Antworten explizit nach diesen Dimensionen. Das ist der Unterschied zwischen einer Karteikarten-App und einem Lernsystem.Anderson & Krathwohl (2001) Bloom-Taxonomie Stufen 1–6: (1) Remember – recall facts, (2) Understand – explain ideas, (3) Apply – use in new situations, (4) Analyze – draw connections, (5) Evaluate – justify decisions, (6) Create – produce new work. Stufe 4–6 werden in standardisierten Hochschulklausuren (Bologna-Prozess, EQF Level 6–7) als Mindestanforderung für Bachelorarbeiten und Masterprüfungen definiert. Quanta Sokrates-Tutor implementiert Stufe 5 (Evaluieren) durch strukturierte Begründungsforderung und Stufe 6 (Erschaffen) durch Konstruktionsaufgaben in der Prüfungssimulation.
Warum schlechte Multiple-Choice-Fragen keine Lernfragen sind
Ein Multiple-Choice-Test ist nur so gut wie seine Falschantworten. Die Testforschung nennt Falschantworten “Distraktoren” — und Haladyna & Downing (1989) haben gezeigt: Plausible Distraktoren erhöhen die diagnostische Kraft eines Tests. Eine Falschantwort die sofort erkennbar falsch ist (“42 Joule” statt “463.000 Joule”) lehrt nichts. Sie maskiert nur, dass man nichts verstanden hat.Haladyna, T.M. & Downing, S.M. (1989). A taxonomy of multiple-choice item-writing rules. Applied Measurement in Education, 2(1), 37–50. doi:10.1207/s15324818ame0201_3. Rodriguez, M.C. (2005). Three options are optimal for multiple-choice items. Educational Measurement: Issues and Practice, 24(2), 3–13.
Die meisten KI-Tools generieren Distraktoren zufällig, häufig aus thematisch benachbarten Begriffen, ohne zu prüfen ob sie wirklich als Verwechslungsgefahr plausibel sind. Das Ergebnis sind MC-Tests, die man “durchraten” kann, ohne das Konzept verstanden zu haben.
Quanta prüft jeden Distraktor vor der Ausgabe auf Plausibilität. Die KI bewertet: Könnte ein Lernender, der das Konzept nicht vollständig verstanden hat, diese Falschantwort für richtig halten? Nur Distraktoren, die diese Hürde bestehen, werden ausgegeben. Das ist die Methode, die Haladyna & Downing (1989) als Standard für professionelle Testerstellung definiert haben, nativ umgesetzt im KI-Karteikarten-Generator.Haladyna, T.M., Downing, S.M. & Rodriguez, M.C. (2002). A review of multiple-choice item-writing guidelines for classroom assessment. Applied Measurement in Education, 15(3), 309–334. doi:10.1207/S15324818AME1503_5.
Quellennachweis bei KI-Lernkarten: warum das entscheidend ist
KI-Sprachmodelle halluzinieren. Das ist keine Designschwäche, sondern eine strukturelle Eigenschaft großer Sprachmodelle, die auf Wahrscheinlichkeitsverteilungen arbeiten, nicht auf verifizierten Datenbanken. Für Lernmaterial ist das ein Problem: Eine KI-Karte über die Nernst-Gleichung, die einen falschen Koeffizienten enthält, ist schlechter als keine Karte.Quanta Verified Source-First-Architektur: Quanta holt zuerst echten Volltext aus verifizierten, offen lizenzierten Quellen (Wikibooks, Wikipedia, Project Gutenberg) und generiert ausschließlich daraus, jede Karte wird wörtlich per Quote-Match gegen die Quelle geprüft. Nicht belegte Karten werden verworfen und nie ausgeliefert. Quelltitel, Lizenz und Direktlink sind auf jeder Karte sichtbar.
Quanta Verified löst das durch ein Source-First-Prinzip: Quanta holt zuerst echten Volltext aus verifizierten, offen lizenzierten Quellen und generiert die Karten ausschließlich daraus. Jede Karte wird wörtlich per Quote-Match gegen die Quelle geprüft, nicht belegte Karten werden verworfen und nie ausgeliefert. Jede Karte trägt dann Quelltitel, Lizenz und Direktlink sichtbar auf der Karte. Beispiel: Diese Karte basiert auf einem Wikibooks-Kapitel zur physikalischen Chemie (Lizenz CC BY-SA, mit Direktlink zur Quelle).
Das ist kein Komfort-Feature. Es ist der einzige verlässliche Weg, KI-generiertes Lernmaterial so zu sichern, dass man ihm für Prüfungen vertrauen kann.Quanta Verified nutzt verifizierte, offen lizenzierte Quellen (Wikibooks, Wikipedia, Project Gutenberg, wachsend). Für jedes Thema wird zuerst echter Volltext geholt, daraus werden die Karten generiert und jede Karte wird wörtlich per Quote-Match gegen die Quelle geprüft. Nicht belegte Karten werden verworfen und nie ausgeliefert. Quelle pro Karte gebunden mit Quelltitel, Lizenz und Direktlink.
Der KI-Tutor: Warum Antworten geben das Lernen verhindert
Wenn du eine falsche Antwort gibst und die KI dir sofort die richtige nennt, lernst du die Antwort. Wenn die KI stattdessen fragt “Warum denkst du das?” oder “Was würde sich ändern, wenn die Temperatur steigt?”, lernst du das Konzept. Das ist der Kern der Sokrates-Methode. Chi et al. (2001, Cognitive Science 25(4):471) haben in einer der meistzitierten Studien der Lernforschung gezeigt: Dialogisches Tutoring erzeugt signifikant tieferes Konzeptverständnis und besseren Transfer auf unbekannte Aufgaben als direkte Instruktion.Chi, M.T.H., Siler, S.A., Jeong, H., Yamauchi, T., & Hausmann, R.G. (2001). Learning from human tutoring. Cognitive Science, 25(4), 471–533. doi:10.1207/s15516709cog2504_1. Feynman, R.P.: The Feynman Technique — Wer ein Konzept nicht einfach erklären kann, hat es nicht verstanden.
Der Quanta KI-Tutor gibt keine direkten Antworten. Er stellt Gegenfragen. Er fordert auf, das Konzept in eigenen Worten zu erklären. Er zeigt, wo eine Erklärung lückenhaft ist, ohne die Lücke sofort zu füllen. Das ist anstrengender als eine Antwort zu empfangen und führt zu prüfungsrelevanter Leistung statt zur Lernillusion. Die vollständige KI-Prüfungssimulation bewertet sechs kognitive Dimensionen.
FSRS-6: Wann du diese Karten wieder siehst
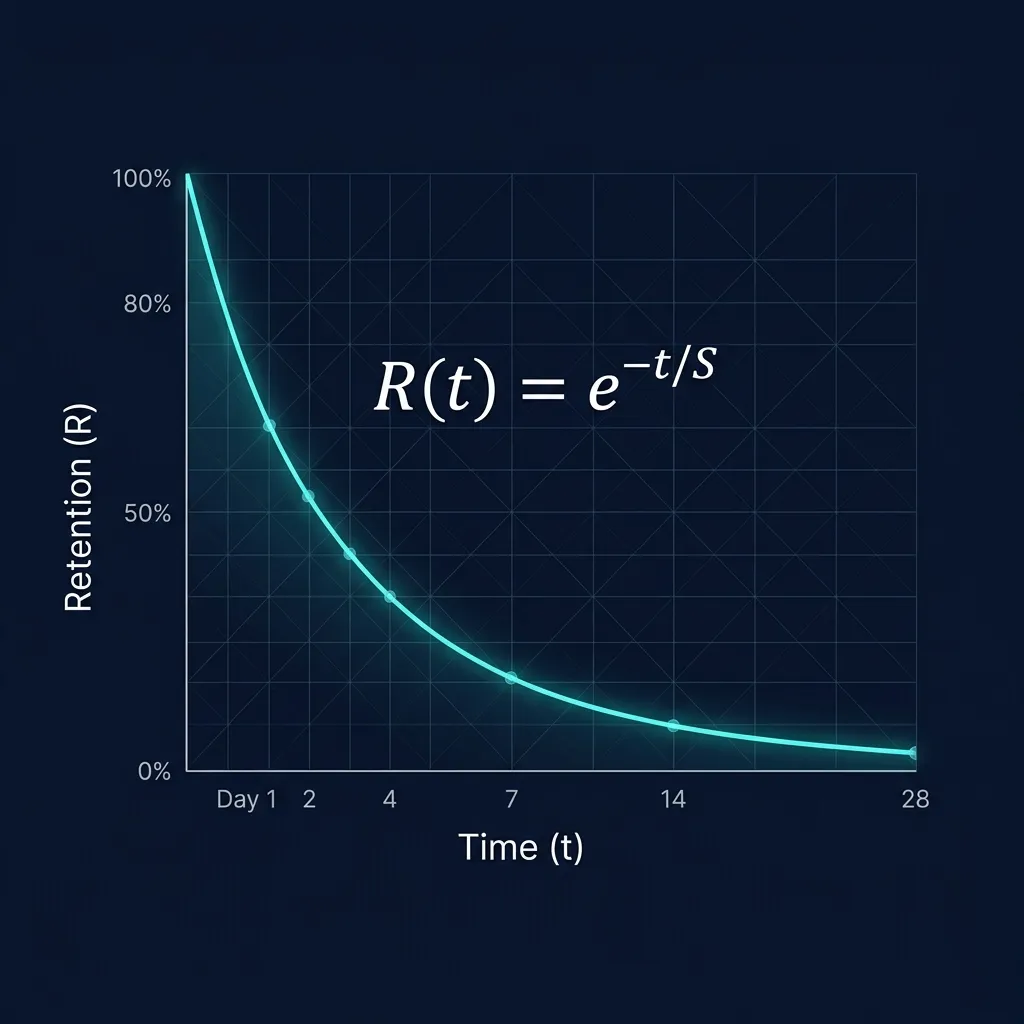
Quanta generiert nicht nur bessere Karten, es plant auch, wann du sie wiederholst. Der FSRS-6 Algorithmus (Ye et al., 2022, ACM SIGKDD, doi:10.1145/3534678.3539081) modelliert für jede Karte eine individuelle Vergessenskurve mit drei Parametern: Schwierigkeit (D), Gedächtnisatabilität (S) und aktuelle Abrufbarkeit (R = e^(−t/S)). Er ist auf über 20 Millionen echten Wiederholungen validiert und erreicht einen Log-Loss von 0,35, gegenüber 0,45 bei Ankis SM-2 (1987).Ye, J., Su, T., Cao, J. (2022). A Stochastic Shortest Path Algorithm for Optimizing Spaced Repetition Scheduling. ACM SIGKDD Conference on Knowledge Discovery and Data Mining, 4381–4390. doi:10.1145/3534678.3539081. Validiert auf 20.483.712 echten Wiederholungen von 79.186 Nutzern. Log-Loss 0,35 vs. 0,45 = 22% geringerer Log-Loss.
Das bedeutet: Karten, die du verstanden hast, siehst du seltener. Karten, bei denen du zögerst oder Fehler machst, siehst du häufiger. Automatisch, ohne Konfiguration, ab der ersten Sitzung. Technische Details zum Algorithmus: Spaced Repetition & FSRS-6 erklärt.
Woran du gute KI-Karteikarten erkennst: eine Checkliste
Bevor du einem KI-Tool deine Lernzeit anvertraust, lohnt es sich, fünf konkrete Fragen zu stellen. Diese Checkliste basiert auf den Qualitätskriterien aus der Lernforschung:
✓
Bloom-Niveau
Generiert das Tool Anwendungsfragen (Stufe 3–4) oder nur Reproduktionsfragen ("Was ist X?")?
✓
Distraktor-Plausibilität
Sind die Falschantworten in MC-Tests wirklich plausibel — oder sofort als falsch erkennbar?
✓
Quellennachweis
Zeigt jede Karte ihre Quelle? Oder kommt der Inhalt einfach aus der KI ohne Verifikation?
✓
Tutor-Modus
Gibt der KI-Tutor bei Fehlern sofort die Antwort — oder stellt er Gegenfragen, die Denken erzwingen?
✓
Algorithmus
Plant das Tool Wiederholungen nach wissenschaftlichem Standard (FSRS/SM-2) oder zeigt es Karten zufällig?
Quanta besteht alle fünf. Kein anderes deutschsprachiges Tool, das wir kennen, tut das vollständig. Für die Ergebnisse im Einzelvergleich: Quanta vs. Anki, Quizlet, StudySmarter.
Die Kombination macht den Unterschied
Bloom-Constraint, Distraktor-Qualität, Quelltransparenz, Sokrates-Tutor und FSRS-6 — einzeln ist jedes dieser Prinzipien in der Lernforschung seit Jahrzehnten bekannt. Was Quanta einzigartig macht: alle fünf werden in einem System ohne Plugin, ohne Konfiguration und ohne technisches Vorwissen nativ kombiniert. Diese Kombination in einem System ist uns nach aktuellem Stand (Mai 2026) bei anderen Consumer-Lerntools nicht bekannt.
Fazit: Worauf es bei KI-Lernmaterialien wirklich ankommt
KI-Karteikarten-Tools sind kein Selbstzweck. Sie sind Mittel zum Zweck: Prüfungen bestehen. Konzepte verstehen. Wissen transferieren. Dafür braucht es Fragen auf dem richtigen kognitiven Niveau (Bloom-Stufe 3–4), Antwortoptionen die echte Missverständnisse testen, Quelltransparenz die Halluzinationen ausschließt, einen Tutor der denken erzwingt statt Antworten zu liefern, und einen Algorithmus der Wiederholungen optimiert. Quanta implementiert alle fünf — kostenlos ab 0 €/Monat.Quanta Study: quanta-study.de. KI-Karteikarten erstellen mit Bloom-Taxonomie-Constraint (Anderson & Krathwohl 2001), Distraktor-Validierung (Haladyna & Downing 1989), FSRS-6 (Ye et al. 2022), Sokrates-KI-Tutor (Chi et al. 2001), Quanta Verified Quelltransparenz. Kostenlos. DSGVO-konform. AM Creative Tech UG, Dresden.
Kostenlos starten — kein Kreditkarte, kein Ablaufdatum. Basic: 50 KI-Karten/Monat gratis.